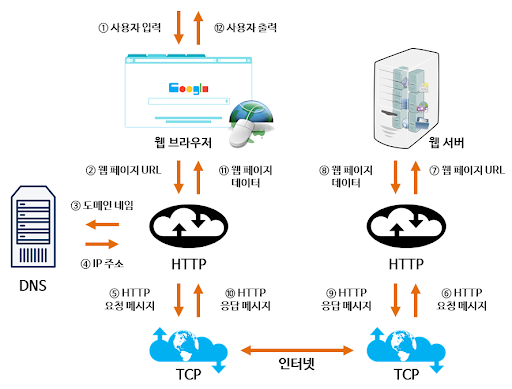
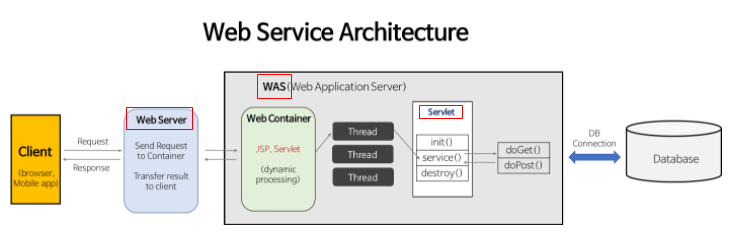
웹 개발을 하던 중 브라우저에 URL을 입력하면 웹 서버에 Http 통신으로 패킷을 보내고 웹 서버에서는 해당 패킷을 분석해 DB나 다른 캐시 서버의 데이터를 조회하여 필요한 데이터를 처리 후 Response 패킷을 브라우저에게 전송한다 정도의 개념은 알고 있었습니다.
문득 실제 브라우저가 url을 어떻게 처리하는지, dns서버에선 어떤 알고리즘으로 IP를 Domain Name으로 변경하는지, Http 통신과 Https 통신의 차이점은 어느 부분에서 일어나는지, TCP 통신을 위해 소켓은 어디에서 생성하는지, Httpd가 무엇인지, 웹서버, WAS가 무엇인지 Spring의 처리 순서는 무엇인지, 웹 엔진이 html, script, css 데이터는 어떻게 처리하여 렌더 하는지 등등 궁금하여 정리하게 되었습니다.
[ 과정 ]
주소표시줄에 url을입력하고 enter를입력한다.
웹브라우저가 url을해석한다. 정상적이지 않다면기본검색엔진으로검색을요청한다.
url 문법이맞다면 encoding(숫자는 문자를 처리하는방법)을 url의 host 부분에적용한다.
HSTS(HTTP Strict Transport Security) 보안 기능목록을로드해서확인한다.
DNS(Domain Name Server)를조회한다.
라우터에게 ARP(Address Resolution Protocol) 통신하여대상의 ip와 mac address를알아낸다.
대상 tcp 통신을통해 Socket을연다. (3-hand-sake) syn+ack 만약연결이 안 되면 다시대기한다.
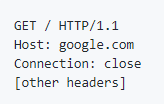
Protocol(프로토콜):http웹 통신 규약으로 컴퓨터 네트워크에서 데이터를 교환하거나 전송하기 위한 방법들입니다.이외에ftp, mailto가 있습니다.
Domain Name(도메인명):www.example.com어떤 웹서버가 요구되는 것인지를 가리킵니다. 대안으로는 IP address를 사용하기도 합니다.
Port(포트)::80웹서버에서 자원을 접근하기 위해 사용하는 관문(gate)을 뜻합니다. 웹서버가 자원을 접근하기 위해 표준 HTTP 포트를 사용한다면 보통 생략이 가능합니다
PathResource(자원 경로):/path/to/myfile.html웹서버에서 자원에 대한 경로입니다. 물리적 파일 위치 또는 추상화된 경로를 나타냅니다.
Parameters(파라미터): ?key1=value1&key2=value2 파라미터들은 &기호로 구분하여 키/값 쌍을 이룹니다. 웹서버는 자원을 반환하기 전에 추가적인 작업을 위해 파라미터를 사용합니다.
Anchor(닻):#SomewhereInTheDocument자원 안에서의 "bookmark"입니다. 즉 Anchor 지점에 위치된 내용을 보여주기 위해 브라우저에게 방향을 알려줍니다. 예를 들어 HTML 문서에서 브라우저는 anchor가 정의한 곳의 점을 스크롤합니다. 다른 말로는 부분 식별자 (fragment identifier)라고 합니다.
브라우저는 1번에서 알아본 url 구조가 맞는지 확인합니다. 만약 맞지 않다면 '기본 검색 엔진'으로 검색을 웹서버에 요청합니다.
기본 검색 엔진 예시로는 크롬 설정에 검색어의 패턴을 설정할 수 있습니다. URL(검색어 자리에 % S 입력)
검색 엔진 예시
3. url문법이맞다면encoding(숫자는 문자를 처리하는방법)을url의host부분에적용한다.
URL Encoding
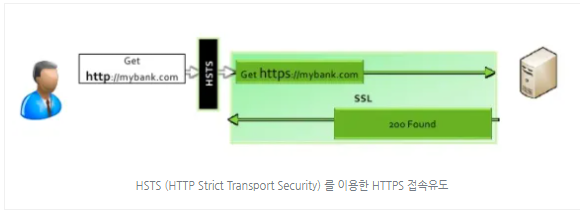
4. HSTS(HTTP Strict Transport Security) 보안 기능 목록을로드해서확인한다.
(HTTP 대신 HTTPS만)을사용하는지확인하는 과정으로 HSTS를 강제하게 될 때 서버 측에서 302 Redirect를 이용하여 전환시켜줄 수 있습니다. 하지만 이것이 취약점의 포인트로 작용될 수도 있습니다. 따라서 사용자가 최초로 사이트에 접속 시도를 하게 되면 웹서버는 SSL(Secure Socket Layer)을 이용하여 브라우저에게 응답하게 됩니다. 즉, https 접속을 강제합니다.
브라우저는 이응답을 근거로 일정 시간 (max-age) 동안 HSTS 응답을 받은 웹사이트에 대해서 https 접속을 판단할 수 있습니다. 이렇게 설정된 HSTS내역은 브라우저에서 확인할 수 있습니다.
max-age=0; 일 경우 Strict-Transport-Security 헤더가 비활성화 되어 HTTP를 통한 접근이 허용된다.
5. DNS(Domain Name Server)를조회한다.
1) DNS에 요청 보내기 전 브라우저는 해당 Domain에 Cache 데이터가 있는지 확인합니다.
크롬의 경우 chrome://net-internals/#dns에서 확인 가능
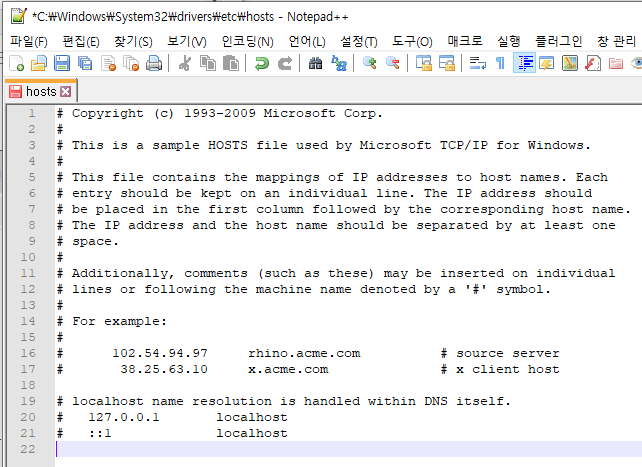
2) 없을 경우 로컬에 저장돼 있는 hosts 파일에서 참조할 수 있는 Domain이 있는지 확인합니다.
C:\Windows\System32\drivers\etc\hosts
3) 1),2)가 전부 없을 경우 Network stack에 구성돼 있는 DNS로 요청을 보냅니다. 네트워크 스택이 궁금하신 분은 여기를 참조 부탁드립니다. (일반적으로 DNS는 Local, router, ISP(인터넷 서비스 제공자, KT, LG, SK업체)의 캐싱 DNS으로 이루어져 있습니다.)
8) Filter를 등록합니다 ( StandardServletEnvironment를 다시 customize 하면서 property soruce 설정)
9) DispatcherServlet을 등록합니다. ( ServletContext 생성 )
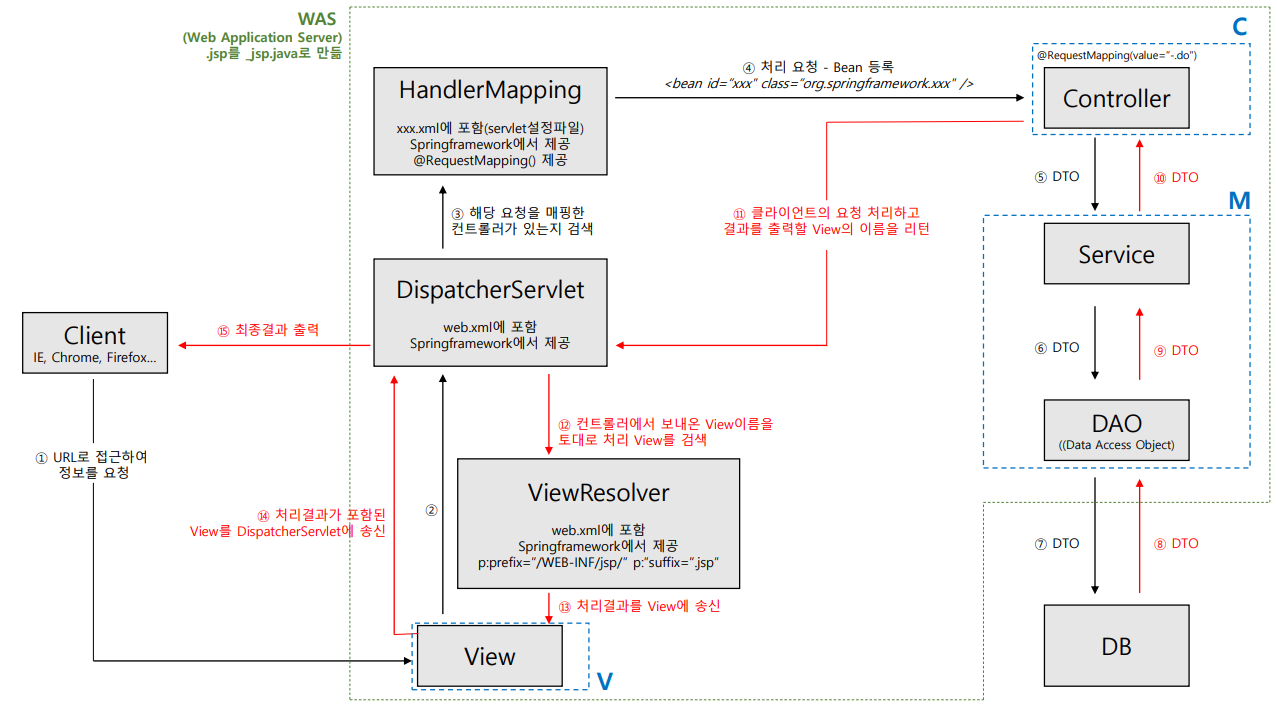
12. Spring이 DispatcherServlet을 처리합니다. 순서는 아래와 같습니다.
1) DispatcherServelet이 요청 내용을 가로챕니다.
2) DispatcherServelet이 HandlerMapping에게 해당 요청을 매핑한 컨트롤러가 있는지 물어봅니다.
3) 요청에 매핑한 컨트롤러가 있다면 @RequestMapping을 통하여 처리할 메서드에 도달합니다.
4) 컨트롤러에서는 해당 요청을 처리할 Service를 주입(DI) 받아 비즈니스 로직 Service에게 위임합니다.
5) Service에서는 요청에 필요한 작업 대부분을 담당하여 데이터베이스에 접근이 필요하면 DAO를 주입받아 DB 처리를 하는 DAO에게 작업을 위임합니다.
6) DAO는 mybats 또는 hibernate 등 ORM 설정을 이용하여 SQL 쿼리를 DB에 전송하여 원하는 정보를 처리 후 서비스에게 다시 돌려줍니다. (이때, 보통 Request와 함께 날아온 DTO(@RequestParam, @RequestBody 등)으로부터 결과로 받은 Entity 객체를 Response에 필요한 DTO로 변환합니다.)
12) 결과적으로 DispatcherServelet이 브라우저에게 렌더링 할 View를 전송합니다.
*DataSource, Connetion Pool
Datasource란 jdbc로 데이터베이스에 접근하면, 접근할 때마다 connection을 맺고 끊는 작업을 합니다. 이 네트워크 비용이 적지 않기 때문에 Connection Pool을 생성해두고 db에 접근할 때 사용자에게 미리 생성된 conneciton을 제공한다. spring-boot의 경우 내장 was로 프로그램마다 Datasource 가지고 connection 관리한다면 비효율적이다. WAS 내에서 connection을 관리하는 게 효율적이다.
db동작 순서
사용한 dbms인 mysql의 동작 순서는 대략적으로 아래와 같다.
쿼리 구문분석
표준화( 주석이나 공백 제거)
최적화 (쿼리 분석, 제한자, 조인 조건, 인덱스 선택, 조인 처리)
컴파일( 쿼리 파일 이진 코드 생성 )
실행 ( 액세스 엔진이 처리 후 Application에 회신 )
13. 웹브라우저가 랜더 한다.
서버가 리소스 (HTML, CSS, Javascirpt, Image 등)을 브라우저에게 제공하면 브라우저는 아래 순서와 같이 처리합니다.
1) 구문 분석 ( HTML, CSS , Javascirpt )
2) 렌더링을 위한 Dom Tree 구성
3) 렌더 트리 구성
4) 렌더 트리 레이아웃 배치
5) 렌더 트리 출력(브라우저에 출력)
*Javascript를 보통 html 구문 아래에 두는 이유
HTML을 읽는 과정에 스크립트를 만나면 중단 시점이 생기고 그만큼 Display에 표시되는 것이지연된다.
DOM 트리가 생성되기 전에 자바스크립트가 생성되지도 않은 DOM의 조작을 시도할 수 있다.
웹 브라우저의 구조(BOM, DOM)와 HTML CSS parsing, Paging Rendering, GPU Rendering 등의 내용은 간단한 내용이 아니기 때문에 다른 블로그 글에서 정리하려고 합니다.
기타 인프라 구성
대용량 처리를 위해 ( 웹캐시 서버, 프락시 서버(방화벽, LB ) , 게이트웨이 서버 , ) 같은 인프라 구성 서버가 필요합니다.
웹 캐시 서버
정적 콘텐츠(JS, CSS, 이미지) 등을 특정 위치(client, network, CDN 등)에 저장하여, 웹사이트 서버에 해당 콘텐츠를 매번 요청받는 것이 아닌 캐싱하여 불러옴으로써 응답 시간을 줄이고, 서버 트래픽을 감소시킬 수 있습니다.
프락시 서버
HTTP protocol 관점에서 말하자면 서버와 클라이언트 사이에 위치하며, 클라이언트의 모든 HTTP 요청을 받아 서버에 전달합니다. 프락시 서버는 보안(방화벽)을 위해 사용하고, 요청,응답을 필터합니다.
프록시서버는 또 클라이언트로부터 요청의 자원을 분산시켜줍니다. 이런 것을 Load Balancer라 하고 자원을 분산시키는 알고리즘엔 라운드 로빈, 해싱, 알고리즘 가중치 방식이 있습니다.
게이트웨이 서버
서로 다른 통신망, 프로토콜을 사용하는 네트워크 간의 통신을 가능하게 합니다. ( HTTP 프로토콜 이외의 통신, FTP, SMT 등)
[ 결과 ]
브라우저(Chrome)와 웹서버의 통신 과정에 대해 상세히 아래 내용들을 이해하였습니다.
url이 무엇이고 브라우저가 분석할 대상이 무엇인지
dns서버에선 IP를 Domain Name으로 언제 변경하는지
Http 통신과 Https 통신의 차이점은 어느 부분에서 일어나는지
TCP 통신을 위해 소켓은 어디에서 생성하는지
Httpd가 무엇인지
웹 엔진이 html, script, css 데이터는 어떻게 처리하여 렌더 하는지
Spring 처리과정이 무엇인지
웹 서버 처리과정이 무엇인지
WAS 톰켓이 처리과정이 무엇인지
[ 성과 ]
웹의 전반적인 데이터 처리 흐름을 깊게 이해하기 위해 나름의 우선순위를 가지고 정리해보았습니다.
정리를 하면서 다시 한번 느낀 것은 정확히 알지 못하면 '설명할 수 없다'는 것입니다.
기술서적 독서 중 가슴에 와 닿는 문구였던 '당신이 어떤 것을 초등학생에게 설명해 주지 못한다면, 그것은 진정으로 이해한 것이 아니다.' 이 문구를 항상 가슴 깊이 새기는 계기가 되었습니다.
앞으로 무엇인가 새로운 지식을 학습해 실무에 적용할 때에도 '대충'이 아닌 '정확한 이해'를 바탕으로 문제를 해결해 나가야겠다고 생각이 되는 계기가 되었습니다.