* 인덱스란 무엇인가?
인덱스는 데이터를 빠르게 검색하기 위해 필요한 존재이다. 예를들면 sql server 참고서적에서 "primary" 라는 단어를 찾고자 한다면
우리는 책 뒤에 있는 색인을 참조하여 찾는다. 하지만 뒤에 인덱스가 없다면 우리는 책 앞부분부터 전체를 뒤져서 찾아야 한다.
데이터베이스에서도 데이터를 찾기위해 테이블 전체를 스캔하느냐 아니면 인덱스를 이용해 그 데이터가 있는곳으로 바로 찾으러 가느냐
하는 성능에 아주 중요한 영향을 미치는 요소 중 하나이다.
그렇다고 인덱스를 사용한다고해서 무작정 좋은것만은 아니다. 인덱스를 만들게되면 그 정보를 유지하기위해 디스크 공간도 필요하게되고
인덱스가 걸려있는 테이블은 인덱스가 없을 때보다 데이터를 추가하거나 변경할 때 더 많은 시간이 소요된다.
이러한 이유로 인덱스를 만들 때 해당 테이블의 용도를 정확히 이해해야한다.
* 인덱스의 종류와 검색
인덱스는 크게 두종류로 CLUSTERED INDEX 와 NON-CLUSTERED INDEX 가 있다.
CLUSTERED INDEX를 생성하게 되면 데이터페이지 자체가 인덱스 키값에 의해 물리적으로 정렬되고,
NON-CLUSTERED INDEX를 생성하면 데이터페이지는 그대로 있고, 인덱스페이지만 정렬된다.
그리고 인덱스에는 UNIQUE를 사용해서 인덱스의 키값이 고유하게 할건지 아닌지를 지정할 수 있다.
- CLUSTERED INDEX
- UNIQUE CLUSTERED INDEX
- NONCLUSTERED INDEX
- UNIQUE NONCLUSTERED INDEX
create table tb(
col1 int,
col2 char(1800)
)
insert into tb values(12,'홍길동');
insert into tb values(14,'안경태');
insert into tb values(28,'김치국');
insert into tb values(27,'오발탄');
insert into tb values(13,'박호순');
insert into tb values(22,'김감자');
insert into tb values(17,'한국인');
insert into tb values(15,'박사내');
insert into tb values(19,'정주고');
insert into tb values(21,'윤기나');
insert into tb values(18,'이리와');
insert into tb values(26,'박치기');
insert into tb values(16,'김새네');
insert into tb values(24,'오리발');
insert into tb values(23,'정말로');
insert into tb values(20,'김말자');
insert into tb values(25,'우기자');
insert into tb values(11,'김박사');
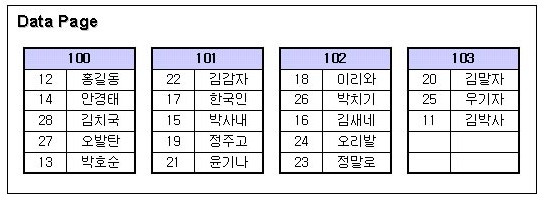
테이블을 생성하고 데이터를 insert 하면 데이터는 데이터페이지에 논리적으로 기록이 된다.
하나의 데이터페이지의 크기는 8kb이며, row수의 필드 크기만큼 저장이 된다.
위 테이블에서 col1 int형은 4바이트 이고, clo2 char형은 1600바이트 이다. 총 1604바이트이다.
하나의 데이터페이지에는 5개의 row가 있으니까 1604 * 5 = 8020바이트 이므로 대충 8kb 이다.
( 대충 계산은 이렇게 하지만 더 복잡한 계산들을 해야한다. 여기선 대충 이런 개념으로만 알고있자. )
100,101,102,103 의 숫자는 각 데이터페이지의 페이지번호이다.
* NONCLUSTERED INDEX
create unique nonclustered index tb_ix_col1
on tb(col1);
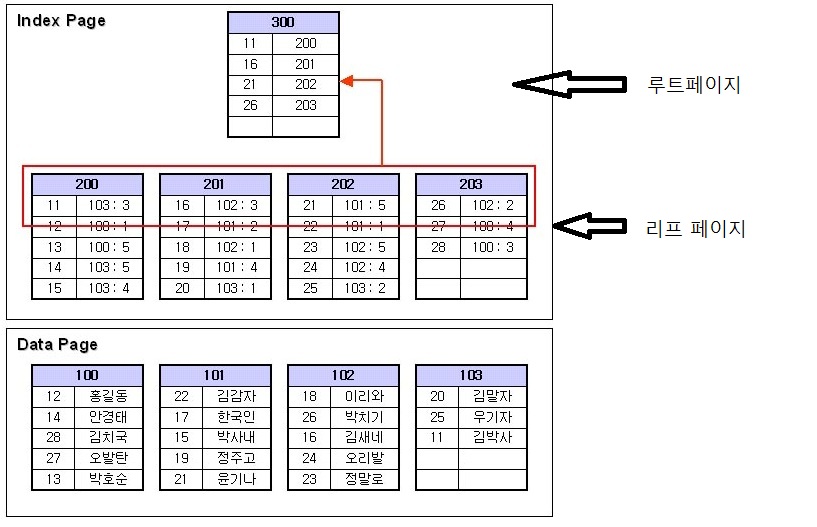
- NONCLUSTERED INDEX 를 생성하게되면 데이터페이지와 같은 인덱스페이지를 구성하게된다.
- 인덱스페이지에는 인덱스를 걸어준 컬럼 즉, col1컬럼의 키값들과 데이터페이지 번호,슬롯번호가 저장되어있다.
( 다른 데이터 정보들도 들어 있지만 여기서는 이렇게만 알고 있자. )
- 인덱스페이지도 데이터페이지와 마찬가지로 크기는 8kb 이다.
(그림에서는 예를들어서 한개의 인덱스페이지에 5개의 행이 있는걸로 표현한 것이다. )
- 가장 최상위에 있는 페이지는 루트페이지이고, 중간에있는 페이지들을 넌리프 페이지이라 하고, 가장 하위페이지는 리프페이지이라 한다.
(루트레벨,넌리프레벨,리프레벨 이라고도 부르고, 위 그림에는 중간 단계인 넌리프 페이지는 없다. )
- 인덱스를 만드는 과정을 살펴보면 데이터페이지를 인덱스 키값으로 정렬을 한 후 리프레벨부터 인덱스페이지를 만들어 간다.
페이지 번호 200에 데이터를 모두 채운 후 데이터가 더 있으면 201페이지에 데이터를 채우고, 이런식으로 계속 리프 페이지를 만들어 간다.
리프레벨이 완성되면 상위의 넌리프 레벨들을 만든다. 상위 레벨을 만들때는 하위 레벨에 각 첫행의 데이터들을 가져와서 만든다.
만약에 하위 레벨에 첫 행들을 가져와 인덱스 페이지를 만들 때 8KB 바이트가 넘어가면 또 옆에 인덱스 페이지를 만들어 데이터를 넣을 것이고,
하나의 페이지에 데이터가 다 들어간다면 더이상 상위 레벨을 만들지 않는다.
이렇게 최상위 레벨에 인덱스페이지가 하나가 될 때까지 만든다.
- 데이터 검색.
select * from tb where col1 = 19
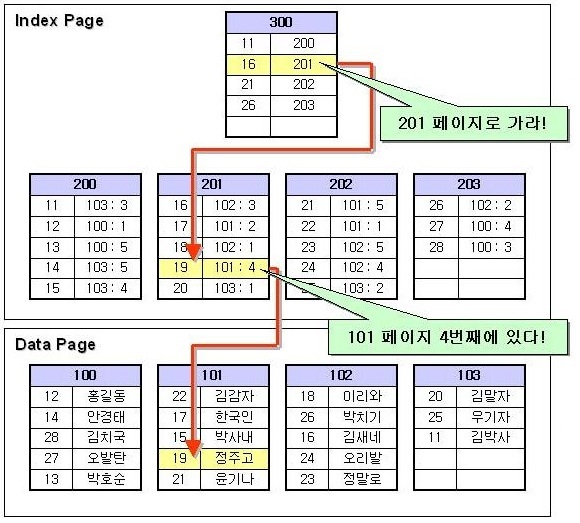
컬럼 col1에서 19 를 검색을 한다면 우선 루트페이지를 가서 검색을하게 된다. 19는 16보다 크고 21보다 작으므로 201 페이지로 간다.
201페이지로 갔더니 19번이 101페이지 4번째 슬롯에 있단다. 그래서 101 페이지로 내려가서 4번째 행의 19의 데이터를 가져온다.
( 유니크한 인덱스와 유니크 하지 않은 인덱스는 조금 다른데 검색을 할 때 유니크하다면 굳이 슬롯번호로 찾지 않고 인덱스 키값만으로
데이터를 찾을 수 있을 것이다. 유니크하니깐.. 유니크 하지 않아 똑같은 인덱스 키값이 2개가 있다면 이 키값만으로 둘중에 어느 것인지
알 수가 없을 것이다. 이럴때 슬롯번호를 이용하여 검색을 한다.)
만약 유니크하지 않은 넌클러스터인덱스였다고 가정했을 때
insert into tb values(19,'김태희');
똑같은 19번의 데이터를 insert 했을 때 데이터페이지에는 어디에 기록이되고 ,인덱스페이지에는 어디에 기록이되는지
19번을 검색했을 때는 어떻게 검색을 하게되는지 생각을 해보자. 각자~
* CLUSTERED INDEX
( 만약 클러스터 인덱스와 넌클러스터 인덱스가 같이 있으면 또 다른 구조가 나온다. )
create unique clustered index tb_ix_col1
on tb(col1);
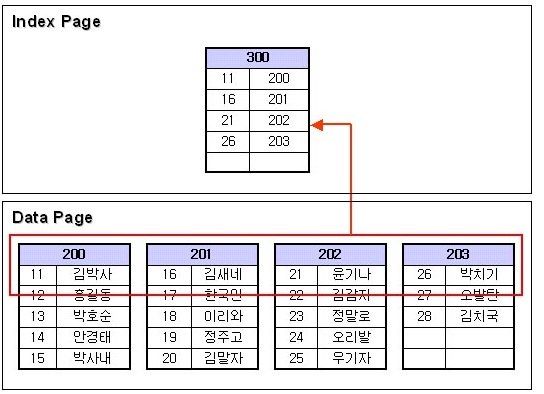
- NONCLUSTERED INDEX와 틀린점이 있다면 CLUSTERED INDEX는 데이터페이지가 곧 리프레벨이다.
즉, 데이터페이지가 col1 값으로 정렬되어 있다. ( 위에 NONCLUSTERED INDEX 보면 데이터페이지는 정렬이 되지 않았다.)
- 데이터 검색
select * from tb where col1 = 19
//자료 100만개 기준으로
넌클러스트 인덱스가있을때와 없을때의 차이.


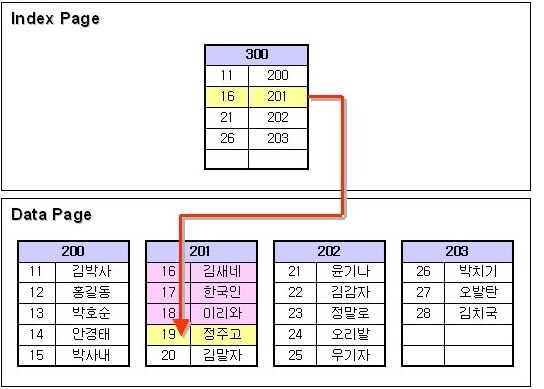
where 조건으로 19번을 찾는다하면 먼저 루트페이지에서 19번 위치를 먼저 찾는다.
19는 16보다크고 21보다 작으므로 201페이지를 찾아 내려간다. 그래서 201페이지로가서 19번을 찾아서 데이터를 가져온다.
* CLUSTERED INDEX + NON CLUSTERED INDEX
위에서는 col1에 CLUSTERED INDEX 또는 NONCLUSTERED INDEX를 생성했었는데
이번에는 col1에는 CLUSTERED INDEX를 col2에는 NONCLUSTERED INDEX를 생성했을 때는 어떻게 다른지 보자.
하나의 테이블에 클러스터 인덱스와 넌클러스터 인덱스가 같이 있는경우는 넌클러스터 인덱스페이지의 구조나 검색방법이 조금 달라진다.
create unique clustered index tb_ix_col1
on tb(col1);
create unique nonclustered index tb_ix_col2
on tb(col2);
인덱스 'tb_ix_col2'을(를) 만들지 못했습니다. 이 인덱스의 키 길이가 최소한 1600바이트입니다.
허용되는 최대 키 길이는 900바이트입니다.
(CLUSTERED INDEX는 잘 만들어졌는데 col2에 NONCLUSTERED INDEX를 생성하려고 하니 위와같은 오류가 났다.
그래서 col2에 필드 크기를 char(6) 으로 하고 다시 만들었다.)
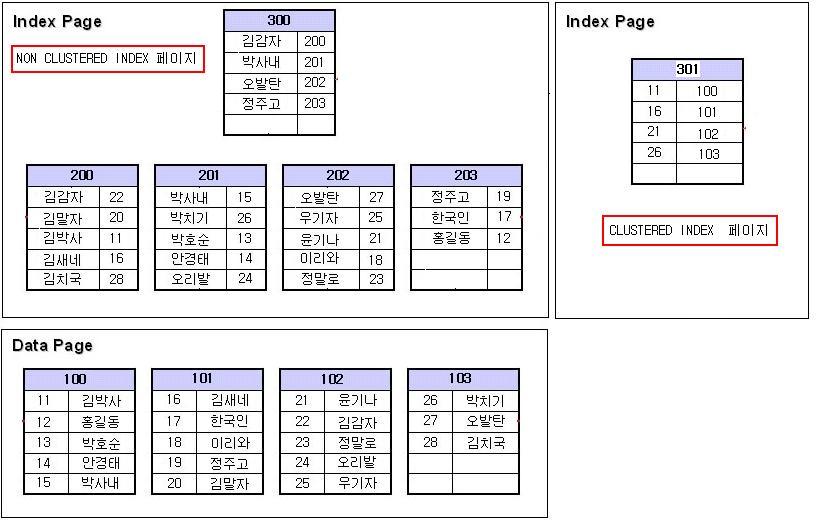
- NONCLUSTERED INDEX 페이지를 보면 NONCLUSTERED INDEX의 키값으로 정렬되어 있고,
CLUSTERED INDEX의 키 값이 같이 저장되어 있다.
- NONCLUSTERED INDEX는 CLUSTERED INDEX의 키값을 가지고 있어서, 데이터페이지의 데이터가 변경되더라도
노드들의 재조정 및 스플릿 현상이 일어나지 않아서 데이터의 변경속도가 빨라진다.
- 하지만 NONCLUSTERED INDEX만 있을때의 비해 검색속도는 떨어진다. 리프레벨에서 바로 데이터페이지로 데이터를 찾아가지 않고,
CLUSTERED INDEX로 가서 다시 탐색을 해야함으로 추가단계와 시간이 더 필요하게 된다.
- 데이터 검색
select * from tb where col2 = '오발탄';
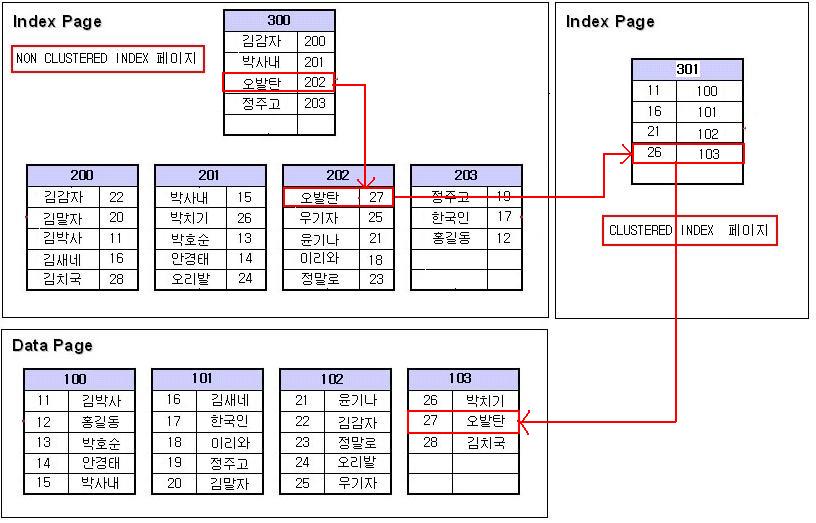
where 조건에 col2 는 NONCLUSTERED INDEX 이니 NONCLUSTERED INDEX 페이지를 먼저 검색하게 된다.
루트페이지에서 '오발탄' 을 찾았더니 202페이지에 있다. 202페이지로 가니 오발탄은 CLUSTERED INDEX 키값(col1) 27을 가지고
CLUSTERED INDEX 루트페이지로 간다. 루트페이지에는 26보다 크니 103페이지를 가리킨다. 103페이지로 가니 '오발탄' 이라는 데이터가 검색되었다.
* 복합 인덱스(Composite Index)
여러 컬럼에 하나의 인덱스를 생성할 수 있는데 이를 복합인덱스(Composite Index)라고 한다.
복합인덱스는 컬럼의 순서에 영향을 받는다. 예를들어 (컬럼1,컬럼2)는 (컬럼2,컬럼1)과는 다른 인덱스 구조를 갖고 있다.
그리고 인덱스를 이용할 때 (컬럼1,컬럼2)로 되어있는 경우 컬럼2만으로 조건 검색을 하게되면 인덱스를 사용하지 않는다.
컬럼2 + 컬럼1 순서로 조건 검색을 하면 순서에 상관없이 인덱스를 사용한다. 항상 첫번째 컬럼이 조건절에 명시되어 있어야 인덱스를 사용하는 것이다.
create index tb_ix_col -- 어떤 인덱스인지 명시해주지 않으면 nonclustered index이다.
on tb(col1,col2);
sp_helpindex tb -- tb테이블의 인덱스정보를 확인한다.
![]()
select * from tb where col2 = '오발탄'

실행계획을 보면 Index Scan 이다. Scan이란 그냥 데이터페이지를 전부 뒤져서 데이터를 찾는것이다.
즉, 인덱스를 이용해서 데이터를 찾은것이 아니다.
select * from tb where col2 = '오발탄' and col1 = 24

실행계획을 보면 Index Seek 이다. Seek란 인덱스를 사용해서 데이터를 찾는것이다.
위에서 설명했듯이 첫번째 컬럼으로 지정해준 컬럼이 조건절에 꼭 있어야 인덱스를 사용하는 것이다.
// 인덱스 검색효율
if OBJECT_ID('orders') is not null
drop table orders
go
select * into orders from Northwind.dbo.Orders
go
declare @i int
declare @EmployeeID int
set @i = 1
select @EmployeeID = MAX(employeeid) from dbo.orders
while (@i <= 999)
begin
insert into orders
select customerId,(@EmployeeID + @i) as employeeId,OrderDate,RequiredDate,ShippedDate,ShipVia,Freight,ShipName
, ShipAddress,ShipCity,ShipRegion,ShipPostalCode,ShipCountry
from Northwind.dbo.Orders
set @i = @i + 1;
end
go
select COUNT(*) from orders
2개의 넌클러스터 인덱스를 순서만 다르게 생성했다.
create nonclustered index order_x01
on orders(employeeid,orderdate)
create nonclustered index order_x02
on orders(orderdate,employeeid)
1. 모든 컬럼에 equal 조건을 사용했을 때
똑같은 equal 조건인 쿼리에 각각 인덱스 힌트를 주어서 서로 다른 인덱스를 사용하게 했다.
set statistics io on
set statistics profile on
select * from orders with(index=order_x01)
where employeeid = 1
and orderdate = CONVERT(datetime,'19980226',112)
select * from orders with(index=order_x02)
where employeeid = 1
and orderdate = CONVERT(datetime,'19980226',112)
set statistics io off
set statistics profile off
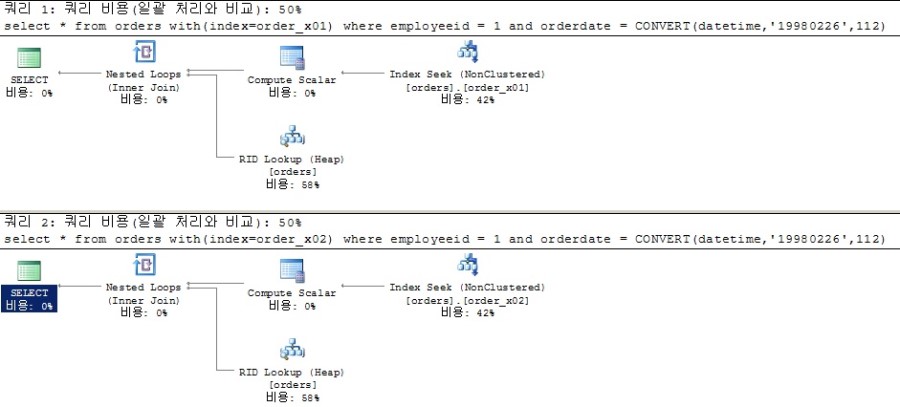
(2개 행이 영향을 받음)
테이블 'orders'. 검색 수 1, 논리적 읽기 수 5,
(2개 행이 영향을 받음)
테이블 'orders'. 검색 수 1, 논리적 읽기 수 5,
두 쿼리의 비용(50%)과 논리적 읽기 수가 똑같다.
두 쿼리의 성능이 같은 이유를 알아보자.
select employeeid,orderdate from orders with (index = order_x01)
select orderdate,employeeid from orders with (index = order_x02)
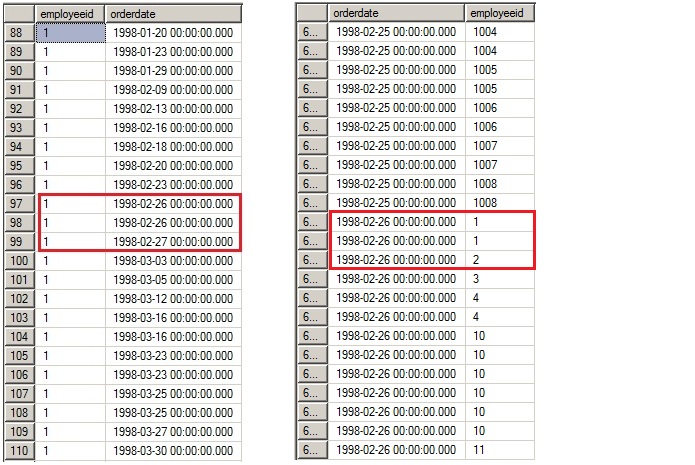
두 컬럼의 조건에 만족하는 2건의 데이터를 찾고 그 다음행까지 찾고나서 멈춘다. 3개의 행을 검색해서 2개의 데이터를 가져왔다.
모든 인덱스 컬럼에 equal 조건을 사용하면 인덱스를 가장 효율적으로 탐색하게된다.
2. 선행 컬럼에 between 조건을 사용했을 때
set statistics io on
set statistics profile on
select * from orders with(index=order_x01)
where employeeid = 1
and orderdate between CONVERT(datetime,'19980226',112)
and CONVERT(datetime,'19980227',112)
select * from orders with(index=order_x02)
where employeeid = 1
and orderdate between CONVERT(datetime,'19980226',112)
and CONVERT(datetime,'19980227',112)
set statistics io off
set statistics profile off
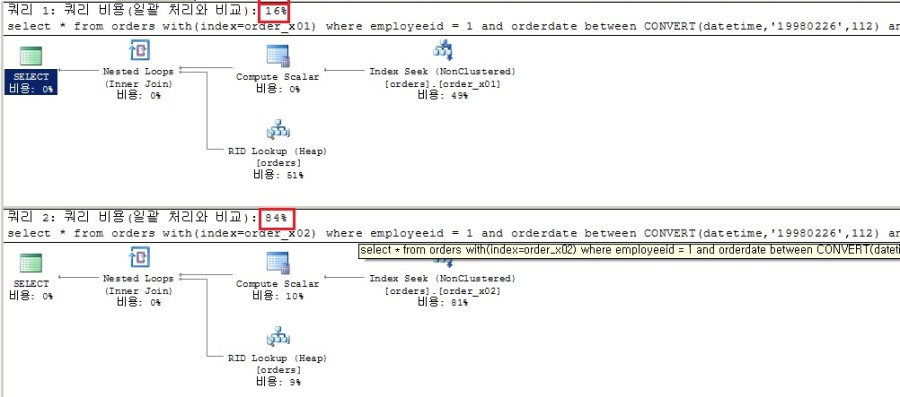
(3개 행이 영향을 받음)
테이블 'orders'. 검색 수 1, 논리적 읽기 수 6,
(3개 행이 영향을 받음)
테이블 'orders'. 검색 수 1, 논리적 읽기 수 26,
두 쿼리의 비용이 7배정도 차이가난다. 논리적 읽기 수도 첫번째 쿼리의 성능이 더 좋다.
두 쿼리의 성능차이가 발생한 이유를 알아보자.
select employeeid,orderdate from orders with (index = order_x01)
select orderdate,employeeid from orders with (index = order_x02)
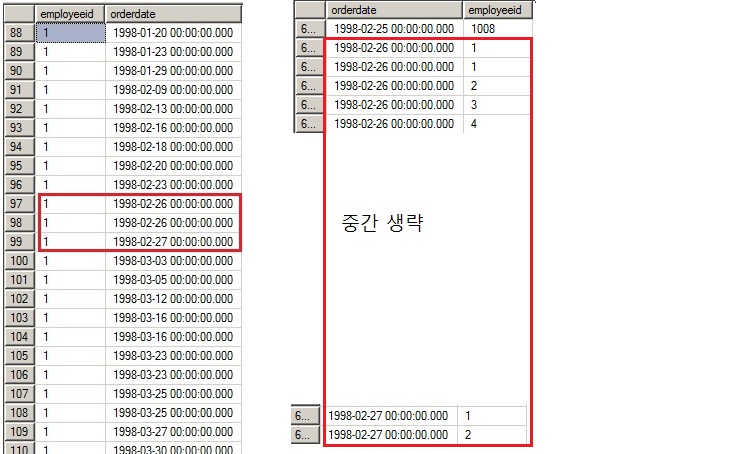
왼쪽 그림은 employeeid 컬럼에 equal 조건을 사용했으므로, 두번째 컬럼인 orderdate가 인덱스 범위를 결정하게 된다.
오른쪽 그림은 order_x02 인덱스에서 불필요하게 넓은 범위를 액세스한다. 인덱스 선두 컬럼인 orderdate에 between 조건을
사용했으므로 employeeid 컬럼은 필터 역할밖에 할 수 없다.
복합인덱스에서 어떤 컬럼의 선행 컬럼에 모두 qual 조건을 사용했지만, 이 '어떤' 컬럼에 between 조건을 사용했다면
나머지 후행 컬럼은 인덱스 액세스 범위를 줄이지 못한다. 예를들어 ( a+b+c+d )로 구성된 인덱스를 'a= , b between , c= ,d=' 조건으로
검색한다면 b의 후행 컬럼인 c와 d는 필터 역할만 한다.
그렇다고 아예 필터역할을 못하는것은 아니다. 오른쪽 그림에서보면 employeeId가 2에서 멈췄다. (빨간색 박스의 내용을 검색 한것이다.)
검색조건이 employeeid = 1 니깐 2까지 검색을하고, 조건에 맞지 않으니 딱 저기까지 검색을 한것이다.
'RDBMS(mysql,mssql)' 카테고리의 다른 글
| 복제DB(replication db) 와 Bulk Insert (0) | 2020.06.20 |
|---|---|
| [MSSQL] MSSQL 실습 (0) | 2018.08.03 |
| [MSSQL] 다수의 데이터 INSERT (0) | 2018.08.03 |
| [MSSQL] 14.트리거,커서 (Trigger, Cursor) (0) | 2018.08.01 |
| [MSSQL] 15.인덱스(INDEX) (0) | 2018.08.01 |